Postings on science, wine, and the mind, among other things.
Constructing a 3-D affect dictionary with word embeddings
Quantifying the emotion in text using sentiment analysis with weighted dictionaries
For ten days this month, I had the pleasure of attending the Methods in Neuroscience at Dartmouth (MIND) Computational Summer School. This year marked the second MIND, and my second time in attendance. Last year I went as a student. This year I returned as "faculty" (in the real world I'm still a postdoc) to give a talk on my research and an in-depth tutorial on representational similarity analysis (you can view the tutorial in RNotebook form online here). Like last year, MIND was a great experience, with the opportunity to learn about cutting edge methods for analyzing a wide variety of neural, behavioral, and text data. One feature that makes MIND different from many older psych/neuro summer schools is its hackathon. Although the morning and early afternoons are given over to lectures and tutorials, the late afternoons and evenings are reserved for hacking on projects of students' own choosing. Last year I hacked my way through several projects. This year I did less of my own hacking, in the interests of focusing on students' projects. However, I did have time to do a couple of small projects in my downtime, one of which is the subject of this post.
Sentiment analysis refers to the process of analyzing text - such as books, letters, emails, text messages, tweets, comments, and status updates - to determine their emotional or affective content. Sentiment analysis is one of the most popular forms of text analysis, particularly in psychological science, where the emotion in text can provide a unique window into a variety of mental processes. The most common form of sentiment analysis involves determining the valence - positive or negative - of text. The simplest way to do this involves what is called a "dictionary" approach. In this approach, the analyst builds up a dictionary of positive and negative words. Then, when it comes time to assess the valence of any given piece of text, they simply count up how often words of each type appear. If more positive words than negative words appear, the text is positive, and vice versa if more negative words appear.
However, people's mental states - their thoughts and feelings - are multidimensional. For instance, in recent work, I found evidence that the brain encodes knowledge of others' mental states in a three-dimensional representational space. These dimensions consist of rationality (vs. emotionality) and social impact (high intensity social states vs. others), in addition to valence. Thus, I wanted to create a dictionary which could allow people to measure the sentiment of text along all three of these dimensions of mental state representation. In the process, I also wanted to address the major limitations of other popular sentiment analyses.
Existing sentiment dictionaries
In psychology, LIWC, Linguistic Inquiry and Word Count, is the most popular tool for quantitative text analysis. LIWC consists of a set of overlapping dictionaries which allow researchers to measure not just emotional content, but dozens of psychologically important dimensions from text. In the decade or so since its creation, LIWC has allowed psychological scientists to use text to study the mind in ways they could not have imagined previously. However, LIWC does have a number of limitations.
First, for any particular dimension, its dictionaries are rather small. For instance, for assessing emotional valence, it only has a few hundred positive and a few hundred negative words. This might not be too problematic when analyzing long samples of text like articles and books. However, these days researchers are increasingly focusing their attention on social media text from places like Twitter. In a 280 character tweet, there simply aren't very many words. As a result, in many cases none of the LIWC positive or negative words might appear in significant fraction of tweets, making it impossible to measure their valence.
Second, the LIWC dictionaries are not weighted. Emotional words are simply classified as positive or negative with no shades in between. Thus, to LIWC, good, great, and amazing are all just (+) and bad, awful, and terrible are all just (-). Again, in large enough samples of text, simply counting (+/-) can somewhat overcome this limitation. However, especially in small text samples, this lack of nuance limits the resolution of LIWC's sentiment assessment.
Finally, LIWC is closed source and you have to pay for it. At ~$90 for a license, the cost is not exorbitant when compared with other important academic software packages *cough* Matlab *cough* SPSS *cough*. However, given the choice between free, open source software and costly, closed source software, if they're roughly equivalent, I'll take the former any day.
The first two issues I raise are not unique to LIWC. For example, in R's qdap package, the polarity function provides a relatively sophisticated sentiment analysis which takes into account some elements of syntax as well as merely counting positive and negative words. It's dictionaries are much larger than LIWCs, at around 6000 words, but still quite small compared to the total size of the lexicon, and still unweighted. In constructing a new sentiment dictionary (or really, set of dictionaries) for my 3-D model of mental state representation, I wanted to address these two major limitations of many existing sentiment dictionaries.
Constructing 3D affect dictionaries
To construct a 3-D affect dictionary, I began with ratings of 166 mental states words on 16 psychological dimensions (described in this paper). These ratings were provided by 1205 participants on Amazon Mechanical Turk, with average values freely available online here. Principal component analysis (PCA) suggested that these 16 dimensions could be reduced to four orthogonal components, three of which ultimately proved able to explain patterns of brain activity associated with thinking about others' mental states. Thus, I began with PCA scores on three psychological dimensions: rationality, social impact, and valence. Due to the large number of raters, these scores were highly reliable numerical values, which solved the first problem, of how to achieve a weighted rather than binary dictionary. However, at only 166 words, the size of this dictionary was smaller even than LIWC's.
To expand the size of the dictionary, I relied on cutting edge techniques for semantic text analysis: word vector embeddings. There are several such embedding systems, such as Word2vec and GloVe. I chose to use one of the latest such system, called fastText. All word vector embeddings are based on co-occurrence statistics - that is, how often the different words appear close together in text. The intuition is that semantically related concepts will tend to co-occur in text. The version of fastText which I used was trained on the Common Crawl - 600 billion words, or basically the entire internet. Researchers in this domain have found that quantity outweighs quality in terms of extracting accurate semantics from text: a small, carefully curated corpus might outperform a more haphazard corpus of a similar size, but usually cannot compete with corpora orders of magnitude larger, no matter how unfiltered. FastText reduces this enormous corpus of words to a single matrix of numerical values: 300 vectors wide by 2 million words long. The 2 million words are key here, because they will allow us to extrapolate ratings on our 166 mental state words to virtually every word in the language.
To extrapolate to the 2 million words in the pre-trained fastText corpus, I fit a radial basis function support vector regression (SVM-R) to predict ratings of 166 mental state words on 3 principal component dimensions (rationality, social impact, and valence). This was possible because those 166 words are themselves included in the fastText corpus. The SVM-R helped solve the "curse of dimensionality" issue with this data set (and ordinary regression with 300 variables and 166 observations is impossible to fit uniquely). This regression achieved relatively high accuracy in 5-fold cross-validation: r = .86, .85, and .91, respectively; RMSE = .60, .60,, .51, respectively, vs. chance at SD=1. You can see the results below.
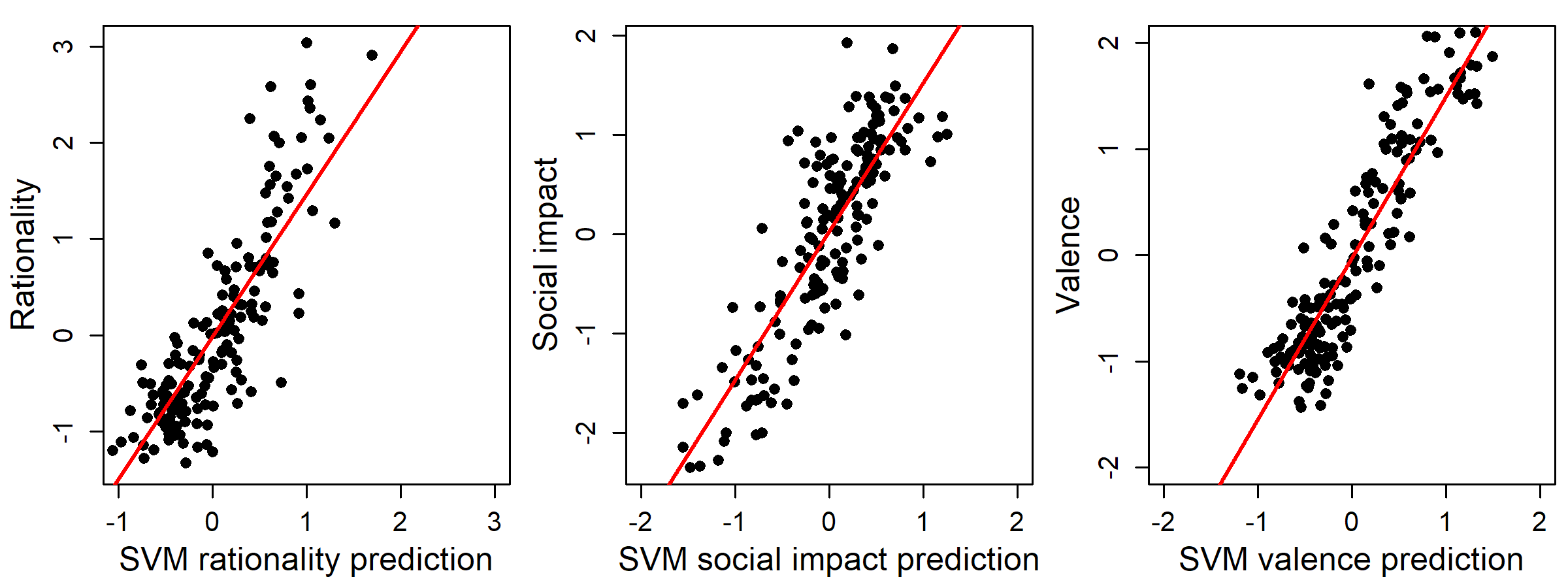
Clearly, this approach allows for highly accurate out-of-sample prediction of our three affect dimensions. Thus, I then trained an SVM-R trained on all 166 state words to impute 3-D affect scores to all 2 million words in the fastText corpus, creating an extremely extensive weighted dictionary. With this dictionary, virtually any sample of text, however small, could be assigned a weighted numerical score on rationality, social impact, and valence.
Validating the 3D affect dictionaries
The next step in this process was to validate the accuracy of the dictionary more extensively. To do so, I began with a very extensive set of human-rated emotion norms. Warriner and colleagues (2013) collected ratings on valence, arousal, and dominance for nearly 14 thousand English words. I correlated these ratings with the predictions made by the SVM-R for valence, social impact, and rationality, respectively. Resulting correlations were .57 for dominance-rationality, .27 for arousal-social impact, and .67 for valence-valence. This reliable out-of-sample prediction, particularly for the exact dimension match of valence to valence, suggests that my dictionary creation method was largely successful.
The final step in validating these dictionaries was to evaluate their ability to classify extended passages of text. To this end, I compared them to the 14k ratings from Warriner et al. in terms of scoring sentences from Amazon reviews, entire IMDb reviews, and sentences from Yelp reviews. These validation data were curated as part of Kotzias et. al,. KDD 2015. Each sentence/review was labeled with a binary 1/0 for positive vs. negative, which I attempted to predict using the valence dimensions of both the 3D affect and 14k rating dictionaries. Results favored the 3d affect dictionary over the 14k human rated words for two of the three validation sets despite the far smaller set of words originally normed in the affect dictionary: Amazon - 60% vs 69% accuracy; IMDb - 73% accuracy vs. 70% accuracy; and Yelp - 73% accuracy vs. 69% accuracy. This superior performance was achieved in part - though not completely - due to the fact that the 3d affect model was able to score every piece of text due to its large number of tokens.
The results of this validation analysis suggest that reliable annotation of a relatively small set of "anchor" words - the 166 mental states, in this case - combined with word embedding systems such as fastText, Word2vec, or GloVe, can construct weighted affective/semantic dictionaries that outperform much larger purely hand-annotated dictionaries. Note that the 14k ratings of Warriner et al. are a particularly tough test case against which to compare, in that they have a couple orders of magnitude more words (with weighting) than common sentiment analysis tools such as LIWC. The code used to construct and validate the 3-D affect dictionaries is freely available online here. You can download the dictionaries themselves in a portable (csv) format here.
The 'affectr' package
To make it easy for others to use the weighted 3-D affect dictionaries I constructed, I wrapped them in a minimal R package which I called 'affectr'
(online here). With the devtools
package installed and included, the affectr package can be installed in R using the command:
devtools::install_github("markallenthornton/affectr")
Within the package, the affect3d function loads the 3-D affect dictionary described in this post (it will take a while the first time the function is called, since the library doesn't)
load until needed) and conducts sentiment analysis on a given text string. Internally it calls the more general sentiment function, which can also be used to conduct sentiment analysis
(or other semantic text analysis) using custom weighted (or binary) dictionaries of your choice. At the moment, that's effectively the only functionality the package provides, but if you'd like to add
to it, feel free to fork the repo on github and submit a pull request!
Conclusion
Thanks for reading this post on the creation of a new set of affect dictionaries to permit sentiment analysis with respect to the dimensions of rationality, social impact, and valence derived from my neuroimaging research. I hope you learned something about quantitative text analysis, and that the dictionaries/R package I created may prove useful to you in the future. If you're a cognitive neuroscientist with a computational bent, I'd also highly encourage you to apply for MIND next year so you have the opportunity to work on similar (and much cooler) projects in their hackathon.

© 2018 Mark Allen Thornton. All rights reserved.