Postings on science, wine, and the mind, among other things.
Understanding Action
How do people conceptualize and predict others' actions?
Action is a not a common topic of study in mainstream US social psychology. That is not to say that social psychologists do not study specific actions or behaviors. Rather, I mean that they do not generally study action as a class or domain. This stands in contrast to other domains which social psychologists do study as a class, such as emotion. Indeed, there is an entire pre-conference at SPSP – the field’s main convention – devoted to emotion. There is no equivalent for action. The domain of actions, as such, has largely been ceded to cognitive psychology. In that subfield, you will commonly see conferences or talk series called things like “Concepts, Actions, and Objects” (often given the humorous pronunciation “chaos”).
Despite my subfield’s apparent lack of interest in action, my long-time collaborator Diana Tamir and I have recently published not one, but three papers on the topic of action:
- Thornton, M. A., & Tamir, D. I. (2022). Six dimensions describe action understanding: the ACT-FASTaxonomy. Journal of Personality and Social Psychology. 122(4), 577-605.
[Paper] [Preprint] [Data & code] - Thornton, M. A., & Tamir, D. I. (2020). Perceiving actions before they happen: Psychological dimensions scaffold neural action prediction. Social Cognitive and Affective Neuroscience, 16(8), 807-815.
[Paper - open access] [Preprint] [Data & code] - Thornton, M. A., & Tamir, D. I. (2021). People accurately predict the transition probabilities between actions. Science Advances, 7(9), eabd4995.
[Paper - open access] [Preprint] [Data & code]
What were we thinking? In this blog post, I will provide an accessible summary of this research. I will then go on to discuss why I think that social psychology has largely ignored the action domain until recently. I will conclude by advancing the argument that social psychology could benefit from developing a greater interest in action. Along the way I will provide some commentary on the processes of doing the research described in the papers – the sort of narrative details of research that don’t really belong in scientific papers, but about which I think scientists are often curious.
My research on this topic originally emerged out of my interest in mentalizing: how people understand each other’s thoughts and feelings. By the time that I started my action research, I had written several papers on mentalizing. The results suggested that a small set of psychological dimensions (such as valence – whether a state is positive or negative) organize the way people mentalize. They also suggested that the reason why we use these specific dimensions to understand others’ minds is because they help us to accurately predict how others are going to think or feel in the future.
Doing this research made me start to wonder about the ultimate value of mentalizing – why do we bother trying to understand others’ minds? The fairly unoriginal conclusion I came to was that we mentalize because it helps us to predict others’ actions. After all, people aren’t telepathic or telekinetic - they can't help us or hurt us with their minds alone. Rather, to affect us, their mental states must be cashed out in terms of concrete actions – ranging from a sustained campaign of complex activity or a quick twitch of a facial expression. Not all mentalizing immediately subserves this goal of action prediction – sometimes we just want to understand a person better. However, I think that much of the ultimate value in understand mental states comes from the help they provide us in predicting the vagaries of human behavior. For example, imagine a world in which people’s emotions never – ever – affected (or even predicted) people’s behavior. Do you think people would bother to attend to each other’s feelings in a world where they were so completely detached from action?
This line of reasoning was what initially got me interested in studying action. It became clear to me that I could not fully understand mentalizing without also understanding the concrete actions to which mental states were tied. I found that there was quite a bit of existing research on actions. However, I also found that relatively little of it targeted the specific questions that I had about the topic. Most of this research had been done by psychologists or neuroscientists in other (non-social) subfields. This doesn’t make it bad by any means, but it did mean that the research questions and approaches were somewhat different from what I was looking for. So, while I continued studying mentalizing, I also began a new line of research into actions.
Paper 1: Taxonomizing actions
My first goal was to come up with a good description for the domain of actions. Specifically, I wanted to discover the psychological dimensions that describe the way people thinking about actions. In other words, I wanted to create a taxonomy of action concepts.
One aspect of my previous work which has always dissatisfied me is its reliance on prior theories. I think it’s good to engage with prior theories, but it is bad to be entirely reliant on them. In my original work on mentalizing, I generated candidate dimensions for my new theory by synthesizing existing dimensions in the psychological literature. This turned out to work quite well in this case, but it might not have done. Specifically, if there was a really important dimension that no one had ever thought to research previously, we would not have been able to discover it using our approach.
In my new work on actions I wanted to address this potential weakness of my prior work, so I took a more data-driven approach. I collected large bodies of text from two very distinct sources: the social media and news aggregation platform reddit, and the Internet Movie Script Database (IMSDb). These sources differed in many ways, including the people who produced the text, the subjects that were discussed, and the intended modality of the communication (written vs. spoken) among other features. This was a deliberate choice on our part: the idea was to find candidate action dimensions that generalized across both bodies of text. We reasoned that any dimensions that could generalize across such different sources would also stand a good chance of generalizing to many other contexts as well.
Within each body of text, we calculated how often each verb (as a proxy for actions) co-occurred with each noun. This analysis was based on the principle that actions are largely defined by the agents that perform them, and the objects or agents that are acted upon, both of which are frequently represented by nouns. I used a statistical algorithm called principal component analysis (PCA) to distill the co-occurrences down to a smaller set of dimensions. We retained eight candidate dimensions, because doing so maximized generalization across the two bodies of text. We also did some initial validation by using these dimensions to classify which subreddit (subject-specific forum within reddit) a separate set of reddit comments came from. Our candidate dimensions outperformed an alternative set of dimensions at this task.
We now had some initial candidate dimensions to describe actions. However, at this point these were just numbers, with no interpretable meaning attached to them. To name these dimensions and give them definitions, we went through an iterative exploration process. Initially, we ourselves looked at the actions that were at the ends of each dimension to try to figure out what distinction each dimension was making. On this basis, we came up with initial names and definitions. We then had online participants rate a subset of actions with respect to these names/definitions, and compared their ratings to the numbers which had come out of the PCA. After repeating this process several times, we eventually found names/definitions which were a good match for each candidate dimension from the PCA.
Across a series of three studies, we had participants make similarity judgements about actions. We used participants’ ratings to gradually pare down the initial set of candidate dimensions into a set that best accounted for the way people judged the actions. The resulting six dimensions were named Abstract/social, Creation, Tradition, Food, Animacy, and Spiritualism (adding “Taxonomy” to the end gave us the acronym “ACT-FAST”. We later learned that this is also the acronym for a stroke intervention program, but it was too late to change it by that point.) The figure below can help you get a better sense for the meanings of these dimensions: each point represents a different action, with some actions near the pole of each dimension labeled in the corresponding copy of the plot.
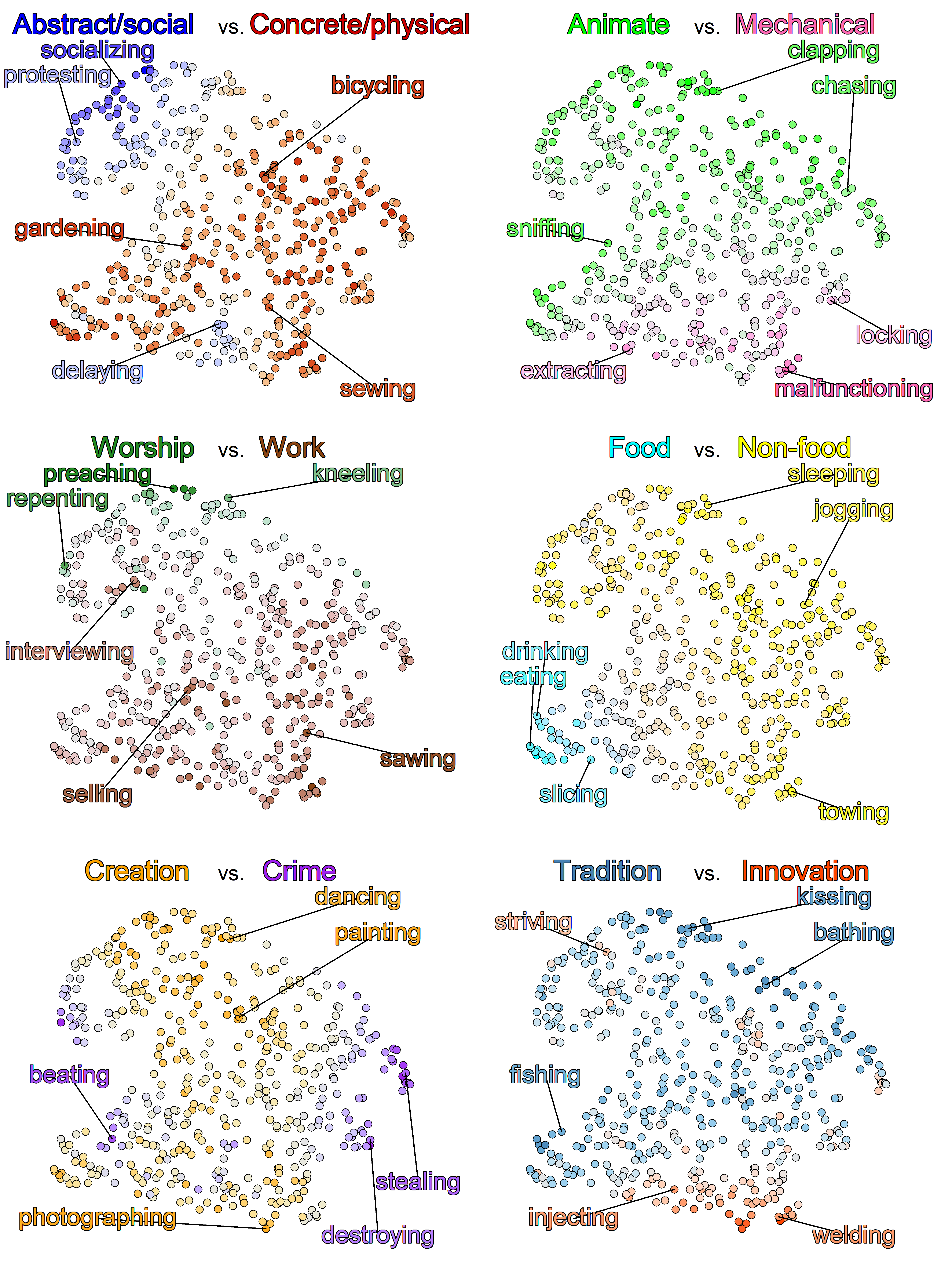
We started our behavioral studies with actions defined as verbs, in part to link these findings directly to the text analysis/PCA results. However, actions and verbs are not quite the same thing. For example, the same verb can be used to describe radically different actions (“running a computer program” vs. “running a marathon”). We took advantage of these verbs with multiple meanings to construct many different phrases around each of a small set verbs. Participants then rated similarity among phrases based on the same verb. The fact that the ACT-FAST dimensions still predicted participants’ judgements when verb was held constant provided further evidence that it was genuinely a taxonomy of action concepts, not just verbs.
In a final behavioral study, asked participants to rate actions (defined as verb phrases) on many different features of practical importance. These features were based around the questions of how, when, why, where, and by whom the actions tend to be performed. For example, is it an indoor action or an outdoor action? Is it a morning or evening actions? What are the traits and motivations of people who perform each action? In total we examined 16 different features. We found that ACT-FAST could statistically significantly predict all 16 of them, even when regressions were trained and tested on different participants and different actions. This provided a powerful test of the taxonomy’s ability to predict the answers to everyday questions about actions.
Our final way of validating the ACT-FAST relied on fMRI. We used an open dataset in which participants in the scanner watched the first half of the first episode of the TV show Sherlock. Using a pre-trained deep learning algorithm, we labeled all of the actions which Sherlock and company performed over the course of the episode. We located each of these actions on the ACT-FAST dimensions, so that each frame of the movie could be “placed” in a 6d “action-space”. We then built a regression model to predict participants’ brain activity from these 6d coordinates. The dataset was relatively small in terms of numbers of participants, but there was a lot of data within each participant, so we treated each of them as if they were their own separate “replication” study. Our regression was able to significantly predict activity in 100% of participants across a wide set of brain regions – from primary visual cortex at the back of the brain all the way towards more socially-aligned regions in the front of the brain. Moreover, we later added an entire second fMRI study to the mix, based upon another open dataset of participants who watch Forrest Gump. These participants were Europeans rather than US Americans, and watched the movie in German instead of English. Nonetheless, a regression trained on our Sherlock-watchers generalized successfully to 100% of the Gump-watchers. Together these fMRI data provide further validation for the ACT-FAST: across data collection method (self-report vs. neuroimaging), stimulus modalities (text vs. video), stimulus (Sherlock vs. Gump), language (English vs. German), and culture (US vs. Europe).
Altogether, this paper yielded a data-driven taxonomy of action concepts which we called ACT-FAST. By identifying a set of psychological dimensions that describe how people think about actions, we laid a foundation for future social psychological research in this domain. Despite the large amount of work we did to derive and validate this taxonomy, I do not view it as the be-all end-all theory in this space. Science is an inherently iterative process, with initial theories giving way to new and improved ones. ACT-FAST can be viewed as the first step in this process, not the last. I look forward to the day when another theory thoroughly supplants it, because that will mean that the field has moved forward in its understand of this important psychological domain. To facilitate this process, we made all of our data from this investigation publicly available on the Open Science Framework. I hope that these data can serve both as a jumping off point for the derivation of new theories, and a common yardstick by which different theories can be evaluated.
In the meantime, ACT-FAST can serve as a useful describe of action concepts, and thereby facilitate a wide range of other research related to actions. The next two sections describe two papers we wrote that were, in part, grounded in this taxonomy.
Paper 2: Action prediction in the brain
The next paper in this series was born of a direct extension of the final study of our action taxonomy work. In that study, we showed that the ACT-FAST dimensions can explain fMRI activity in a large portion of the brain as people watch actions in video. In this second paper, we asked a related question: does the brain’s encoding of where a currently observed action falls on the ACT-FAST dimensions predict which as-yet unseen actions were about to occur next in the narrative of Sherlock?
That question might sound a bit convoluted, but it’s simpler than it sounds. A good analogy is seeing someone’s location on a map. Even without knowing which way they are going, or whether they are traveling on foot, bike, train or car, you can still make a good guess about where they will be an hour later. Specifically, if you guess that they will be somewhere near where they are now, you will likely be right. Of course, there are occasions on which you will be wrong – for example, if they get on a high-speed train they could be quite far away. However, on average, you’d be much better off guessing that someone in New York will still be in New York in an hour, rather than guessing that they will half-way to Philadelphia.
Our hypothesis was that the same was true for actions over time. That is, if you see an action at a certain ACT-FAST location at a given moment in Sherlock, then you would be better off guessing that the next action will be close by in ACT-FAST space, rather than far away.
Instead of just considering which actions objectively participants saw in Sherlock, we wanted to determine where their brains “placed” each observed action in ACT-FAST space. Although it is possible to localize an action concept to a particular set of coordinates, each perceive might judge that a certain instance of a certain action falls in a slightly different location from the average conceptual coordinates. This could be because that one participant differs from other perceivers. For example, perhaps one participant always walks to church, but never walks to work, and therefore associations walking slightly more with the “worship” end of the ACT-FAST dimensions than other participants do. These idiosyncrasies could also be explained by a particular instance of an action being different from the prototypical example people think of when they rate the concept rather than a specific instance. For example, perhaps when you picture “running” in the abstract, you are more likely to imagine a lone individual running, whereas in the narrative, you observed multiple people running together. That could make you view that particular act of running as more social than the abstract concept of running.
To determine where our participants’ brains placed each observed action in ACT-FAST space, we constructed a decoding model which could take in a pattern of brain activity, and return a set of ACT-FAST coordinates. This model was trained on part of the narrative, and then applied to predict ACT-FAST coordinates in the remaining part. We found that our model successfully decoded which actions were occurring as participants watched that part of the narrative. However, more importantly, we also found that those predictions accurately decoded later actions in the narrative that the participants had not yet seen. This study thus provided us with some initial evidence that the ACT-FAST dimensions may play a role in helping our brains predict others’ future actions based on the current actions. We took this idea further in the final paper I will describe next.
Paper 3: Action prediction in the real world
Sherlock is what fMRI researchers call a “naturalistic” stimulus. However, it is only naturalistic in comparison with more typical fMRI stimuli, which often consist of very minimalistic sequences of images or text presented in randomized orders. Compared to these stimuli, Sherlock and other movie-type stimuli are indeed more true-to-life in many ways. Still, movies possess many features that distinguish them from real life. For example, there are hard “cuts” in movies, where visual perspective – or perhaps even the entire scene – changes abruptly. Moreover, movies are narrative created by people to be entertaining. This means that certain mundane actions – like going to the bathroom – frequently get omitted from narratives. While this may enhance our movie-going experience, it distorts the action dynamics in the movie relative to those we might observe in real life. For this reason, we wanted to expand our research on action prediction to a number of different contexts which might get us a bit close to reality.
To do this, we measured the transition probabilities between actions using a several different datasets. Transition probabilities reflect the likelihood of one thing happening after another. For example, if someone is currently chopping vegetables, how likely is it that they will next boil water? Some transitions are more likely than others. Boiling water is more likely to follow chopping vegetables than it is to follow bicycling. You can see an illustration of some of these transition probabilities in the figure below. We wanted to test whether people have good intuitions for which transitions were more vs. less likely. We already had good evidence that people know transition probabilities between emotions, so would they have similar knowledge about actions? And if so, would ACT-FAST capture this knowledge of action dynamics?
The datasets we used to measure transition probabilities between actions included movie scripts, surveys, sets of instructions, and annotated videos. The scripts and videos were both similar Sherlock, in that they were crafted narratives. However, they included hundreds of scripts and video, making the action transitions far more diverse than what we would see in a single TV show episode.
The surveys came from the American Time Use Survey (ATUS). This is a large nationally representative survey conducted every year by the US Bureau of Labor Statistics to help understand how US Americans spend their time. In this survey, people report on all of the activities they engaged in over the course of the previous day, allowing us to measure action transitions in a much more naturalistic and representative way than by using movies. The downside is that these surveys are somewhat coarse – they provide describes of relatively categories of activities that occur over the course of minutes or hours, rather than seconds.
The final type of data we used consisted of sets of instructions from Wikihow.com. These instruction sets consisted of sequences of discrete steps aimed at achieving a particular goal. As with the movie scripts, we measured action transitions by looking at verbs: in this case, which verbs occurred in each step of the instructions and the following steps. Unlike the other datasets, the Wikihow action transitions were purely normative: that is, they indicate what people should do, rather than necessarily indicating what they actually tend to do.
Each of these datasets has some limitations. Each of them is true to life is some ways, but not in others. However, by combining them all, we could get a much clearer picture of whether people can actually predict which action transitions tend to occur in the real world. We did this by asking online participants to rate the transitions probabilities between the same pairs of actions that occurred in each of these datasets. We then correlated participants’ ratings with the actual transition probabilities measured in each “ground truth” dataset. For every dataset, we found that participants’ judgements were reliably correlated with the ground truth transition probabilities, indicating that they have an (at least somewhat) accurate understanding of real-world action dynamics.
In addition to showing that people have accurate intuitions about action transitions, we also examined whether action transitions – whether ground truth or participant rated – were correlated with the ACT-FAST dimensions. Specifically, we tested the hypothesis that the closer two actions were on these dimensions, the higher the transition probability would be between them. Again, for every single ground-truth dataset, we found that proximity on ACT-FAST dimensions predicted transition probabilities – and helped account for the overlap between ground truth and rated transitions. Interestingly, which specific ACT-FAST dimensions accounted for this overlap varied from one dataset to another, suggesting that they may support different types of real world prediction. This result suggests that our action concepts may be tailored to help us more accurately predict others’ actions.
One of the things that gives me confidence in this paper’s results is actually a mistake I made along the way. In what became the paper’s Study 5, I made a programming error which accidentally replaced the actions we intended to select with a semi-random set of actions. Despite this error, people still accurately predicted the transitions between this arbitrary set of actions. I quickly caught and corrected the error – and re-ran Study 5 accordingly – but we still reported our inadvertent data collection as Study 5’ in the supplemental material of the paper. As you can see there, people’s degree of accuracy in this accidental replication was almost exactly in the middle of the range of accuracy we see in all of the other studies. Since not even my mistake could erase this effect, I put a bit more stock in it than I would do otherwise.
Why social psychologists don’t – but should! - study actions
Social psychology – and its close cousin, personality psychology – are arguably both all about explaining why people act the way they do. However, they don’t actually focus on the action itself, so much as the explanation. In particular, both fields tend to focus on the “hidden movers” of the psychological world. That is, the invisible mental properties that shape people’s behavior. These include factors such as mental states, personality traits, and social situations. For example, how do beliefs and intentions come together to influence how a person with certain traits will behave in a certain context?
I agree that these hidden movers are really fascinating, and I have devoted much of my career to studying them. However, the mystery of how things like emotions and social norms work can overshadow the (supposedly) more prosaic world of directly observable actions. We can see and hear actions in a more direct way than we can infer another person’s mental state or personality traits. We also know from both the scientific record and our own personal experience that understanding these hidden movers is ultimately essential to understanding behavior. As a result, I think many of us in social psychology end of taking the actions themselves for granted.
So why is this a problem? How would social psychologists benefit from studying actions more? I think that there are three main ways that doing so could help us:
First, action-to-action prediction can serve as an important baseline against which we can compare more complex models of action prediction. This point gets to the heart of the motivation for studying things like mental states. Why do we as scientists, and we as social agents, care so much about what other people are thinking and feeling? Presumably we eschew pure behaviorism because we recognize that people’s mental states are really potent predictors of their behavior. We are better social predictors because we rely on these latent states, rather than focusing solely on people’s manifest behavior. However, that’s a big “presumably” – exactly how much better a social predictor is the mentalist than the behaviorist? Without studying actions and action dynamics, it is difficult to be precise about the degree and nature of the advantages that understanding mental states confers on people. By taking the naïve behaviorist’s perspective theory – that is, by seeing how well people can predict action based on other actions – we can learn how mental states and other “hidden movers” of the social world contribute to improving our social abilities.
Second, learning more about actions can tell us more about the states, traits, and situations that predict them. For example, William Gibson and the ecological psychologists have argued that situations are composed of the action affordances they offer. This is an interesting and testable hypothesis about how people understand situations. However, we cannot thoroughly test this hypothesis without understanding actions themselves. Without this understanding of actions, we cannot appropriately sample actions to study, nor can we identify how the underlying dimensions of situation space functionally translate into the likelihood of actions in specific parts of action space. That is, we can’t tell which types of situations lead to which types of action, without understanding what the types of action there are in the first place.
Finally, social psychologists hold very diverse interests, many of them highly applied. In these applied contexts, outcomes often ultimately depend on people’s actions, not their thoughts, feelings, or beliefs. For example, if one is interested in reducing social inequity, it may matter more how powerful people act, then why they act that way. At the end of the day, someone doing good for cynical reasons is still doing good. However, without understanding the actions themselves, we cannot determine which actions are best for achieving a certain goal, nor how to motivate them – cynically or otherwise.
If you’ve made it this far – thank you! I hope that this post has given you some insight into the latest research I’ve been doing on action, the reasons I’ve been pursuing it, and why – if you’re a social psychologist – you might want to study actions as well.
© 2022 Mark Allen Thornton. All rights reserved.