Postings on science, wine, and the mind, among other things.
The Structure of Emoji Space
Can psychological dimensions explain the semantic similarity between emoticons?
Since the time of Alfred the Great, the literate have used the Latin alphabet to represent the English language in writing. Alphabetic writing systems like Latin and Cyrillic are very popular in Europe, in part due to the pervasive influences of first the Roman Empire, and later the Christian church. However, alphabets are not the only system which humans have invented for representing thoughts and ideas on a page. For example, Chinese and Japanese use a logographic character system, in which symbols represent entire words or phases, rather than letters.
Recently, with the introduction of new digital methods of communication, the English language has started to adopt a set of standardized, non-alphabetic characters: emojis. Emojis are ideograms - drawings meant to present a broad range of different people, places, things, and concepts. The broad adoption of emojis across texting and a variety of social media platforms is a testament to their usefulness in online conversations, which tend to be less formal and more compressed than traditional written communication.
Emoticons - a portmanteau of "emotional" and "icon" - are graphical representations of emotions. They pre-date the technical implementation of emojis - which are represented by unicode characters - since they can be formed using Latin characters and grammatical symbols (e.g. ":)" for a smiley face). Emoticons now form a subset of emojis - those which represent emotions, typically, though not always, using the traditional yellow smiley face (🙂) as a template.
How do people use emoticon emojis in everyday conversations? In psychology, many people have investigated the structure of emotion "space" - how psychological dimensions or categories reflect and shape our experience and perception of emotions. For instance, you can read about some of my work using fMRI to understand the neural structure of emotion space here. Perhaps the most famous theory of emotion space is the circumplex model (Russell, 1980) which suggest that two dimensions - valence (positive versus negative) and intensity/physiological arousal - can explain much of the structure of human affect. These dimensions have become one of the most common ways to think about emotion in psychology - can they also be used to explain how people use emotional emojis?
Recently, a number of new techniques have been developed which allow us to understand the semantic meaning of words in written text. These word embedding systems, like word2vec capitalize on the co-occurrence of words to infer elements of their meaning, which are then represented on a set of dimensions or vectors. One can then calculate the semantic similarity between a pair of words simply by correlating their coordinates across these vectors. However, there is no reason to limit such analysis to words per se: emojis can also be analyzed in a similar way. Indeed, a team of researchers did just that, applying an analog of word2vec to the textual descriptions of emojis.
The authors of this work kindly posted a pre-trained version of their model - emoji2vec - online here. Coincidentally, I also recently stumbled across another paper in which other researchers had a large set of participants rate a set of emoticon emojis on seven psychological dimensions (they shared these data here). This fortunate open data coincidence allowed me to try answering the question posed. I correlated the semantic emoji-vectors together to estimate their similarity, and then correlated the resulting correlation matrix with the proximities between states on rated psychological dimensions. If a particular dimension shapes emoji-space, then there should be a positive correlation between overall semantic similarity (calculate via emoji2vec) and the proximity between pairs of emoticons on the dimension in question. You can see the results below:
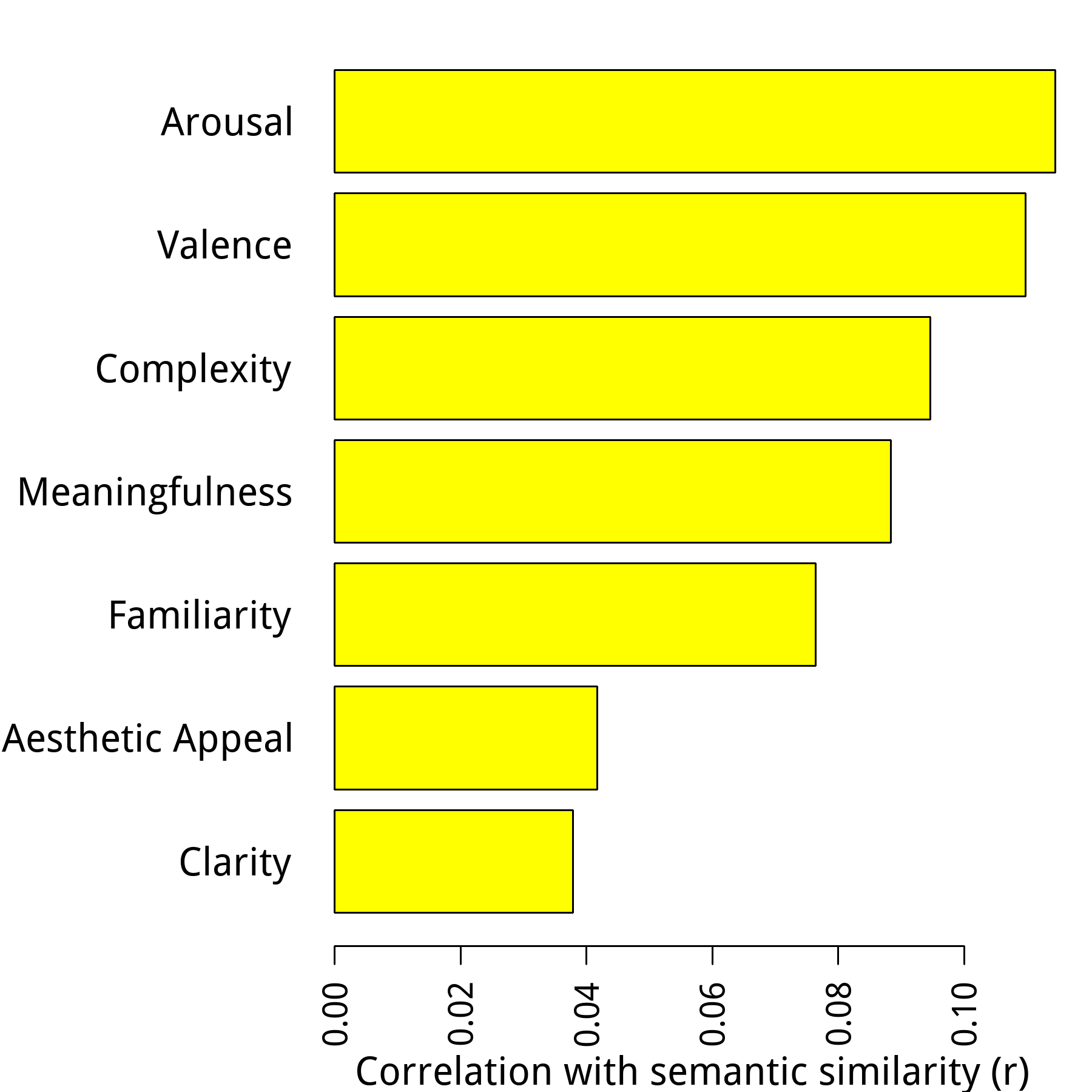
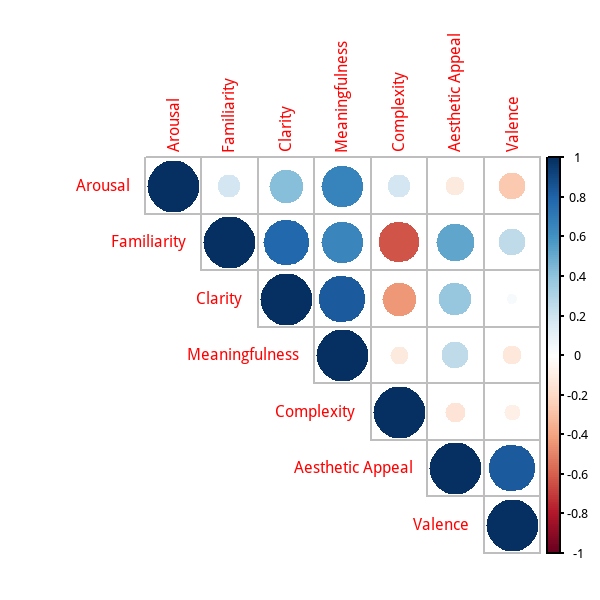
As you can see, all seven rated dimensions were correlated with similary in the expected dimension. Out of the seven, valence and arousal were most correlated with the semantic similarity between emojis. This result thus validates the circumplex model of affect described above. However, what about the other dimensions that seem to correlate with semantic similarity? Well, much of their predictive capacity may be explained by the fact that they are themselves correlated with valence and arousal, as shown below:
Perhaps a larger issue is that, even putting all seven rated dimensions together, we're only explaining a few percent of the total variance in similarity between emojis. Indeed, emoji-space seems genuinely high-dimensional: trying to force a 2-D structure onto the similarity matrix via multidimensional scaling (MDS) produces the configuration below. Unfortunately, this configuration isn't a very good fit. It takes closer to six dimensions to accurate capture the similarity between different emoticons. Coincidentally (or perhaps not?) we found in earlier work that the dimensionality of the neural space of mental states is probably around 5-6 dimensional (even though we only have names for three so far). The arrows you seen on the graph below are called "biplots" and they represent the correlations between the (arbitrary) axes of the MDS graph and each of the psychological dimensions: the longer the arrow, the larger the correlation. The fact that arousal shows the smallest biplot here - despite being the dimension most correlated with similarity - is symptomatic of the bad fit of the MDS. If you extend the MDS to higher dimensions, arousal correlates better with some of the later dimensions that emerge. Unfortunately, it's hard to visualize a 6-D space in a static 2-D image.
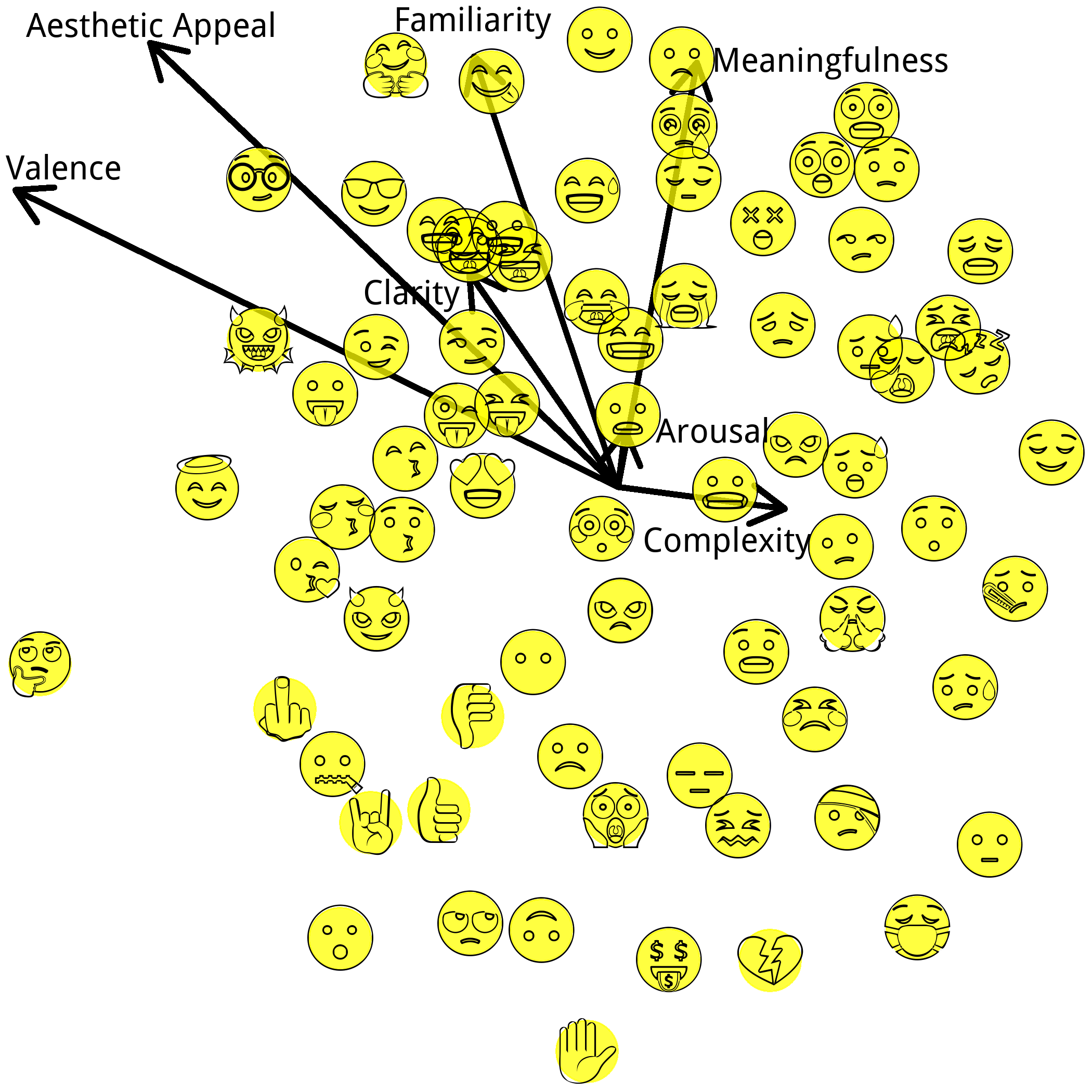
It's worth pointing out that the emoji2vec model used to estimate the similarity between emoticons was trained on the descriptive text for each emoji. These descriptions tend to focus heavily on the physical details of the symbol, rather than their richer semantics. Thus, some of the apparently "missing" dimensions here may be relatively uninteresting surface details of the symbols - such as whether they are face-based or hand-based. A version of emoji2vec trained on actual emoji use, instead of descriptors, might mitigate this tendency, though it could also potentially introduce new linguistic issues.
Before I found emoji2vec, I experimented with a purely co-occurrence based approach to estimating semantic similarity between emoticons in a large sample of tweets collected from US Twitter. I found this space to be very nearly unidimensional, with the one dimension being valence. However, in retrospect, this is probably at least partially artifactual: focusing solely on the co-occurrences between emoticons will suppress any conceptual associations due to arousal, since one migth expect arousal to have a moderating rather than direct effect on co-occurrence. For example, two high intensity emoticons will very rarely co-occur if their valence is different. Running a more complete co-occurrence model, like emoji2vec, would hopefully mitigate this by including other words. For instance, even though "joy" and "rage" might never co-occur, they might each co-occur with the same words indicating extremity (e.g. "very"), thus allowing the influence of arousal to manifest.
So, what's the upshot of all this? It seems like psychological dimensions can indeed explain some aspects of the similarity between emoticon emojis. Moreover, the fact that the two dimensions of the circumplex model - valence and arousal - are most highly correlated with semantic similarity provides a degree of validation for this theory. However, psychological dimensions explain only a small part of the apparent similarity between emojis, perhaps because this similarity is estimated using descriptions rather than contextualized occurrences in real text. Even if this training set does somewhat limit our conclusions, it leaves us with a worthwhile reminder: emojis are visual objects, much like faces, and much like faces, they differ from one another visually in ways that may have nothing to do with underlying emotional dimensions. The datasets used in this blog post are linked above, and the code is available here.

© 2018 Mark Allen Thornton. All rights reserved.