Postings on science, wine, and the mind, among other things.
Analyzing stylistic similarity amongst authors
A quantitative comparison of writing styles in 12,590 books from Project Gutenberg
About one year ago, I finished building a book recommender for the Project Gutenberg collection. To do so, I analyzed the style and content of tens of thousands of the books they freely provide (for more details on precisely how I did this, you can read my earlier blog post). Recently it occurred to me to revisit this data with a slightly different aim. Rather than quantifying the similarity of individual books, I could try to estimate the stylistic relationships between authors. From a practical point of view, such an analysis could serve a similar purpose to the book recommender, except at the slightly coarser level of authors. From an academic perspective, determining quantitatively which authors wrote like each other could prove useful to scholars attempting to resolve outstanding problems in literary theory. The results of this effort can be seen below.
[Hover to see larger; mousewheel to change zoom level; hi-res original 9200x9184]
Authors linked by grey lines have similar writing styles. Node size increases with the log (base 10) of the number of books authored by the writer. Colors indicate natural clusters of authors. To see a particular cluster in isolation, click the button with the corresponding color or read below.
Method
The analytic process began with identifying a set of authors to study. The overall number of authors in the Gutenberg collection is far too high to include in any reasonably interpretable visualization, so I needed to find a way to reduce the set to a more tractable number. There are many ways one might go about culling the population of writers - based on a metric of fame, through some criterion such as time period, or even purely subjectively. The method I chose was admittedly imperfect, but at least had the virtues of being generally effective and minimally inserting my own biases. I simply chose the authors who were in the top 5 percentile in terms of number of their books in the collection. In practice, this equated to having authored at least seven books, a criterion met by some 720 authors.
The obvious flaw in this method is that prolific authors are not necessarily good authors, and even more so, vice versa. That said, another flaw in the data inadvertently mitigates the first issue to some degree: due to the presence of multiple versions and translations, influential authors are likely to have more entries (though not necessarily unique books) in the corpus then less known authors. I did my best to fix this when building the recommender - going so far as to manually comb through the whole book list - but I have no doubt that I failed to achieve perfection. Moreover, particularly in the case of translations, it seemed worthwhile to leave multiple copies of certain books available for the recommender.
Having selected a set of authors, I then went about quantifying their writing style. I'm sure a fair number of people had a viscerally negative reaction to that last sentence, but quantifying style isn't a ludicrous or even particularly new idea. I first became aware of it when I read a very interesting paper in PNAS on the transmission of style over time, but that's hardly the first example of its kind. One type of case in which quantitative stylistic analysis (or "stylometry") has proven very useful is in helping to make authorship attributions for works of uncertain origin. In the statistics lab I teach, I give the students the text of Jane Austen's Pride and Prejudice and George Eliot's Middlemarch to quantify writing style and then ask students to identify which of the two authors wrote a third book (which turns out to be Eliot's Daniel Deronda). Some of my friends have used similar techniques for more serious scholarship.
To quantify style, I take a similar approach to that of the PNAS paper I mention above. For each book, I break down the frequency of standard English "stopwords" (i.e. grammatical words such as articles, pronouns, etc.) as well as punctuation marks. To build my recommender, I then simply took the cosine similarity between different books with respect to these frequencies. However, in this case I first had to combine across all of the books written by the same author. To do so, I first normalized the frequencies by dividing each terms frequency by the sum of all terms for each book. I then took the mean of each word or punctuation mark's normalized frequencies across books. This yielded a single term frequency vector for each author, which I could then compare using cosine similarity. The initial frequency counts were obtained using Python's Natural Language Toolkit, with subsequent analyses being conducted in R.
Having calculated the similarty between authors, I visualized these relationships in network form using igraph. To build the network, I allowed each author to connect to the four other authors with the most similar writing style to them. In the past I've found this technique leads to more interpretable graphs than simply setting an absolute threshold on connection strength. Finally, I used a walktrap community-finding algorithm to cluster the network into coherent groups of authors with similar styles (shown as distinct colors in the graph above). The Fruchterman Reingold algorithm was used to arrange the network as clearly as possible in 2D space.
Results and Discussion
As the network graph above shows, the 720 authors I examined fell into 11 different clusters of varying size and structure. I deliberately avoided naming these clusters above to minimize the effects of my (quite possibly misguided) perceptions upon you, dear reader. In truth, while I may flatter myself by claiming to be fairly well read, I am not a scholar of English or Comparative Literature. Exploring the network above makes this abundantly clear to me, as for each author I know there seem to be at least one or two others I've never even heard. With that considerable caveat in mind, read on to hear my laymen's interpretation of these results.
Cluster 1
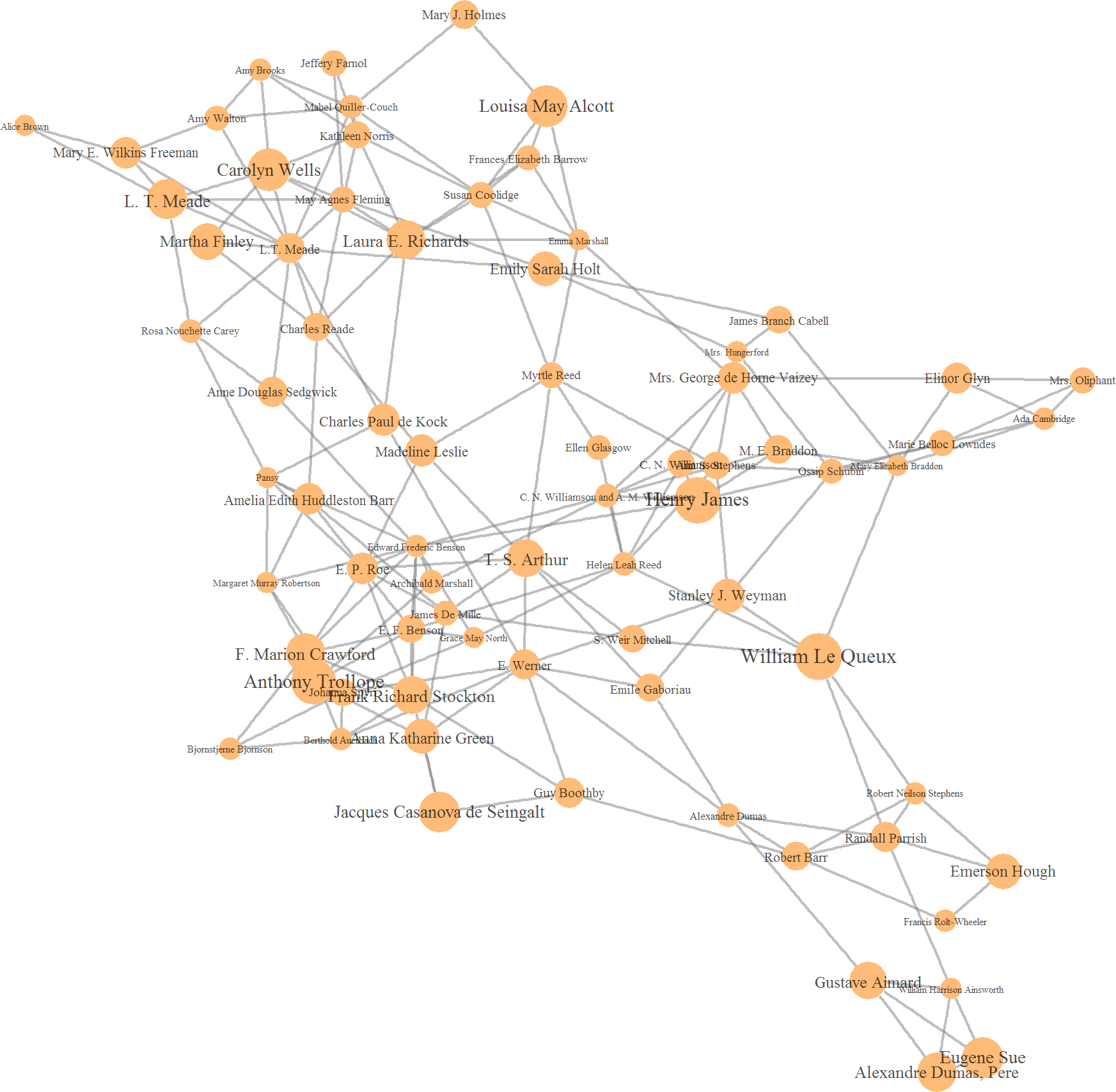
Clusters emerge from the walktrap algorithm in no particular order (so far as I know or can discern), but I'll follow this arbitrary order nonetheless. Cluster 1, shown in peach above, features a number of familiar authors such as Henry James, Anthony Trollope, and Louisa May Alcott. Like most of the cluster, cluster 1 contains mostly original English language writers (though Alexandre Dumas pere et fils, among others, contradict this trend). More notably, this cluster appears to be disproportionally composed of female writers, in comparison to the others. This may hint at historical differences in writing style between genders.
Edit: it's also been suggested that this cluster may place a heavy emphasis on female protagonists and characters generally.
Cluster 2
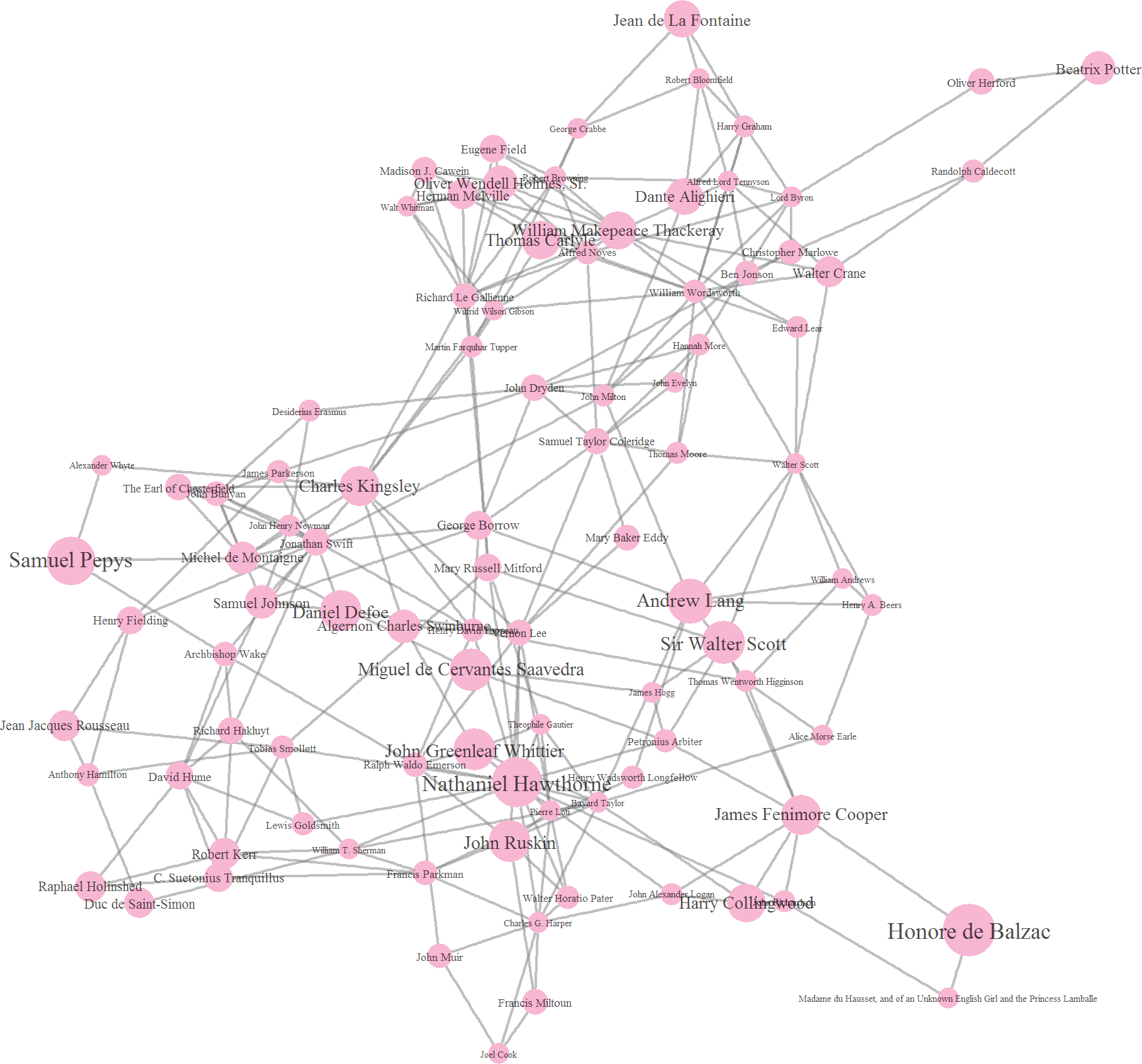
Cluster 2 contains a large number of quite famous writers including Dante, Balzac, Sir Walter Scott, Defoe, and Cervantes, to name but a few. It also contains a substantial number of nonfiction writers, such as Samuel Pepys (diarist), Ruskin (art critic), Montaigne (essayist), Hume (philosopher), John Muir (naturalistic), and Swift (satirist), among others. Some of Britain's greatest poets, such as Coleridge, Wordsworth, Marlowe, and Milton also appear. I am hard pressed to identify the theme of this group, though per capita it may be the most illustrious.
Cluster 3
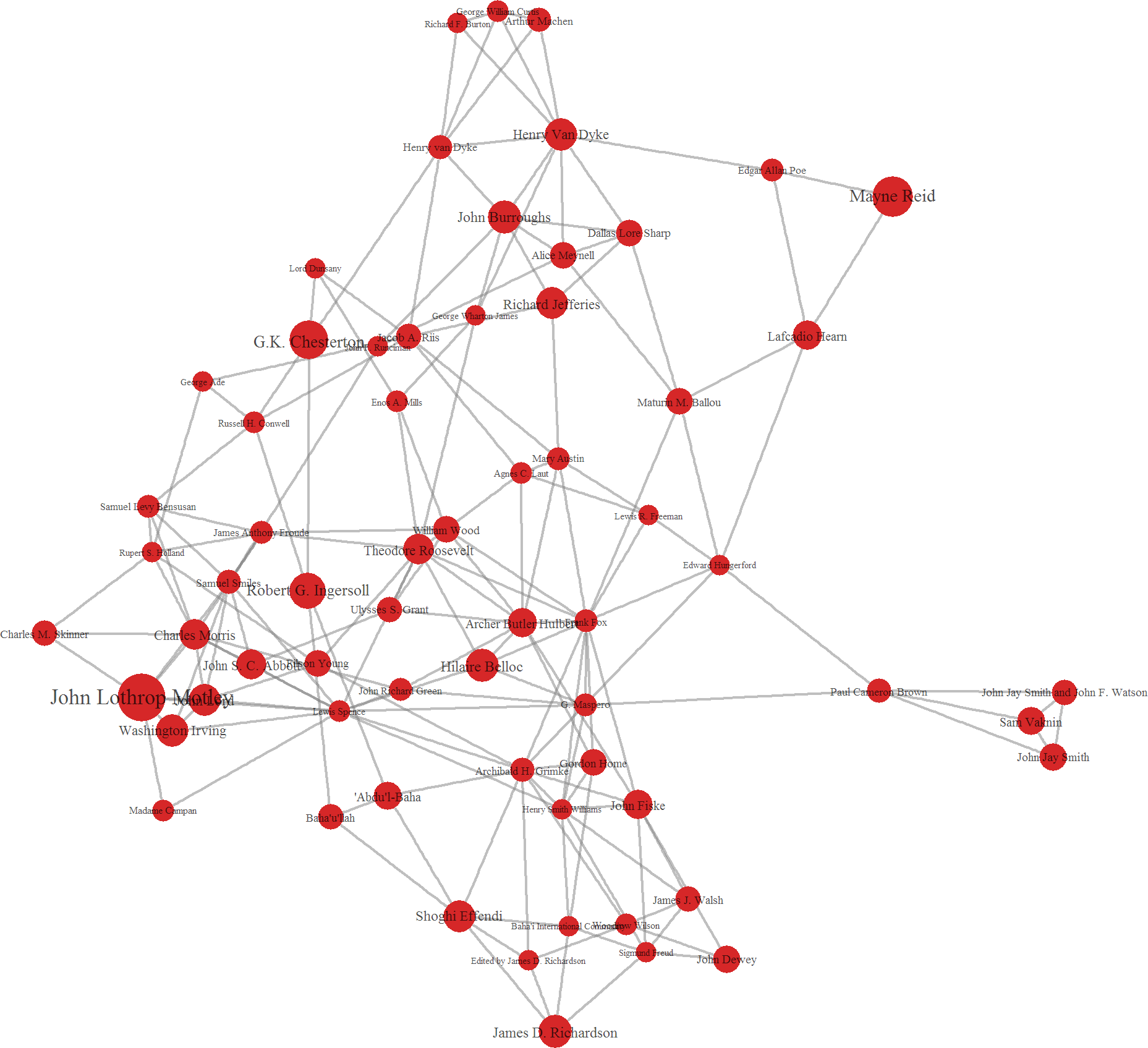
Cluster 3 appears to be heavily political, including statesmen such as Theodore Roosevelt, Woodrow Wilson, and Ulysses S. Grant, as well as diplomats like John Jay and Washington Irving. There is also a definite religious tenor to this group, as it features prominent Christian apologist G.K. Chesterton, "The Great Agnostic" Robert G. Ingersoll, and articles of the Bahá'í Faith. These facts hint that this grouping may derive from an inclination to adopt Biblical style in writing or that authority has a style all its own.
Cluster 4
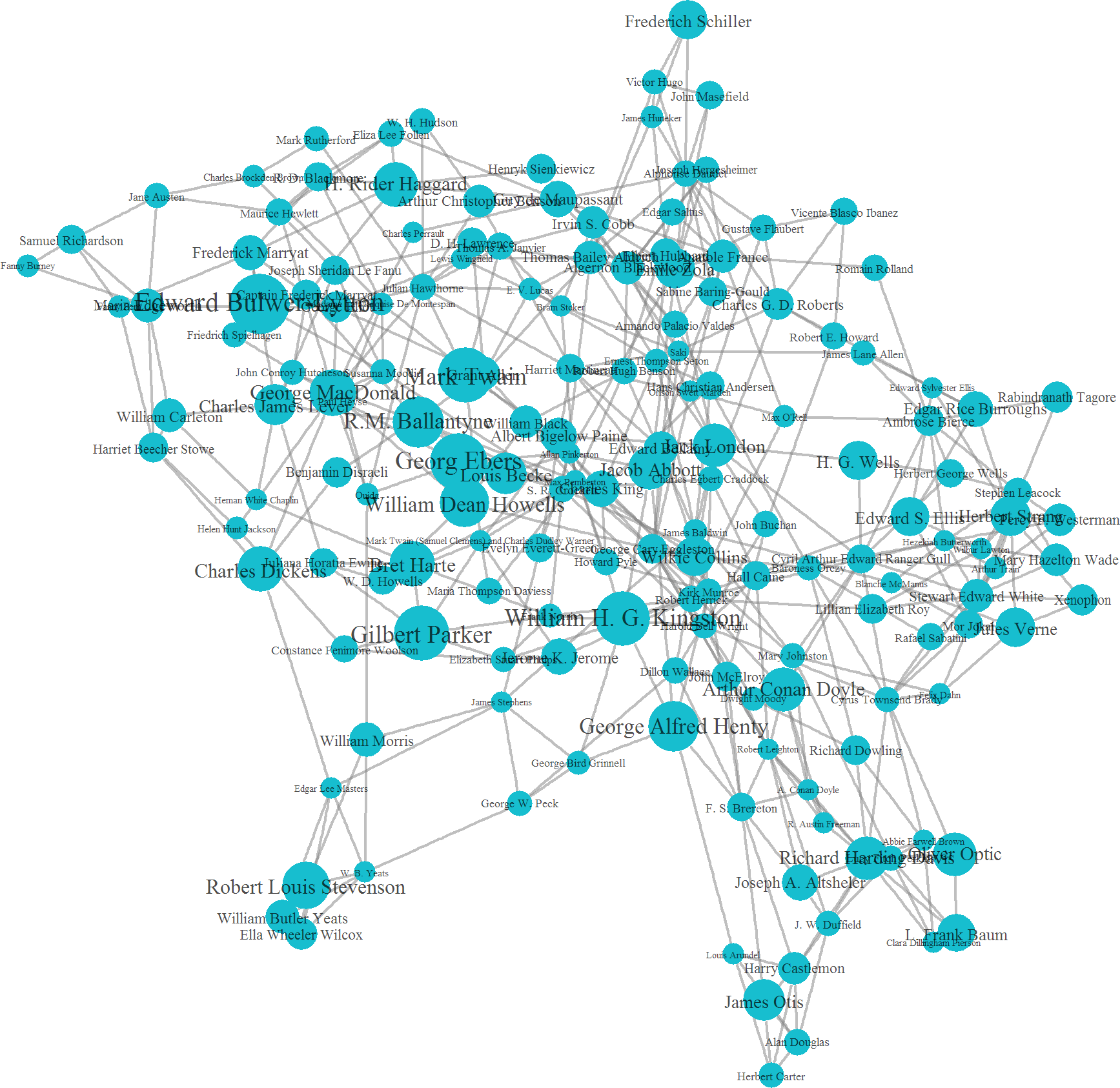
Cluster 4 is the most numerous cluster, and probably not coincidentally also the most central to the overall author network. Its literary greats include, but are not limited to, Jane Austen, Robert Louis Stevenson, Jules Verne, Jack London, Victor Hugo, Frederich Schiller, Mark Twain, Emile Zola, H.G. Wells, Gustave Flaubert, and many, many others. However, there are also many lesser known authors in the group, suggesting that it is not fame that unites these writers. To me, this complex cluster appears to contain a number of smaller subclusters, such as "French, 19th century writers," making the discovery of an overall theme difficult.
Cluster 5

If cluster 2's unifying factor was fame, cluster 5's may be the obverse. I recognize virtually none of the authors in this cluster. Hopefully other people share this impression, and it's not just some particularly deficiency in my own education shining through!
Edit: it appears that this cluster may be populated predominantly by authors of forgotten best-sellers: prolific writers of "genre" fiction that never achieved classic status.
Cluster 6
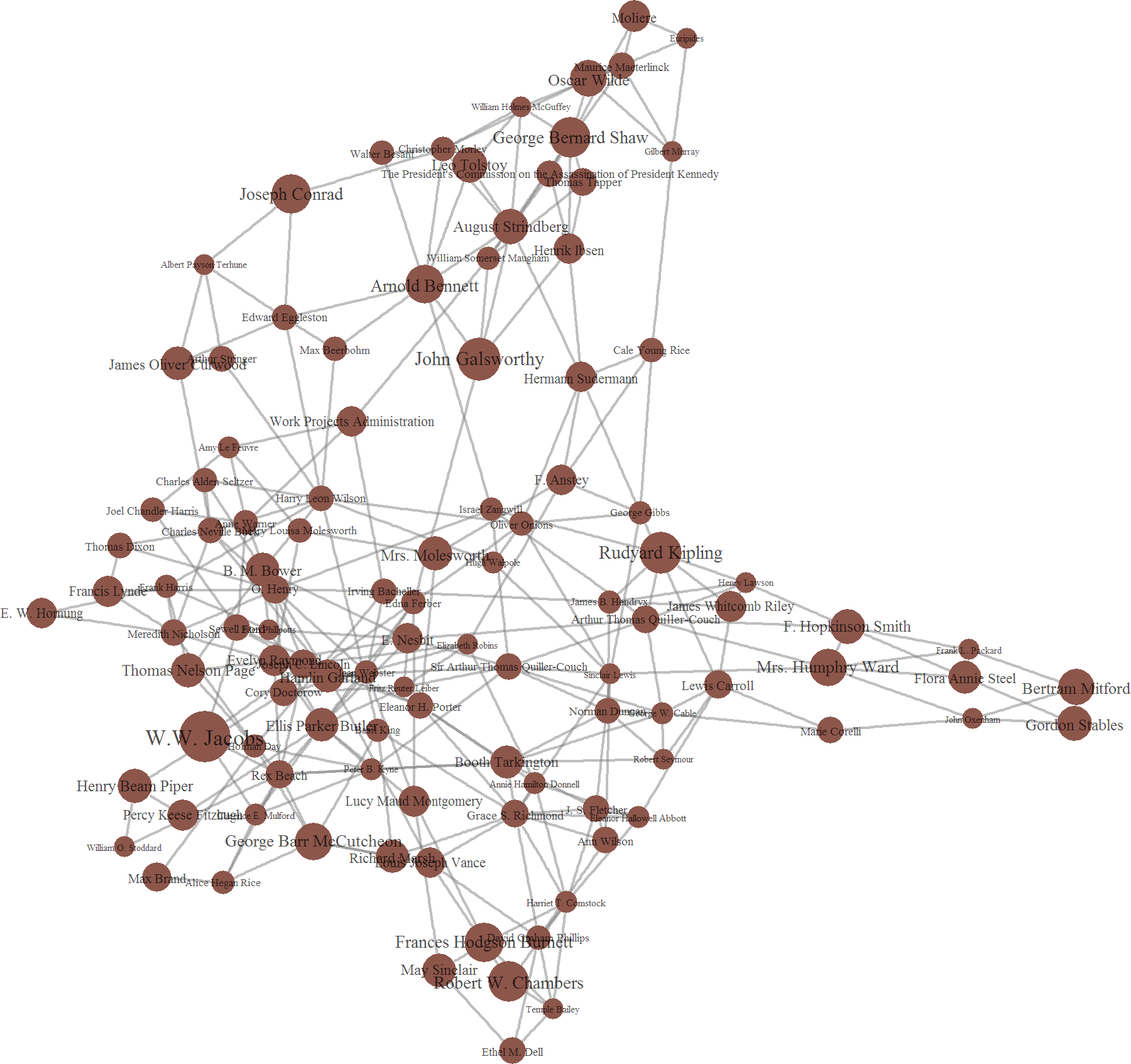
Cluster 6 contains an interesting assortment of writers including George Bernard Shaw, Kipling, Tolstoy, Oscar Wilde, and Moliere. Playwrights feature prominently, but so too do a variety of government sources such as the commission on the Kennedy assassination and the WPA. Given the nature of plays and testimonies, perhaps a focus on quotations unites these works. Interestingly, Cory Doctorow, one of the few contemporary writers to feature in the Gutenberg Collection due to copyright issues, also appears in this cluster.
Cluster 7

Cluster 7 contains a large number of prominent intellectuals including, William James (as I write this, I sit in a building named for him), Charles Darwin, Voltaire, John Stuart Mill, Arthur Schopenhauer, Thomas Paine, Edmund Burke, Plato, Aristotle, Abraham Lincoln, and Martin Luther. It seems that writing about the rights of man, and such things, may carry with it a particularly stylistic vocabulary as well.
Cluster 8

Among cluster 8's most well known denizens are Winston Churchill, Edith Wharton, Anton Chekhov, and Upton Sinclair. This cluster heavily overlaps with cluster 6 described above, suggesting some higher order relationship between the two groups of authors. Beyond this, I fairly puzzled by the constituency of this cluster.
Cluster 9
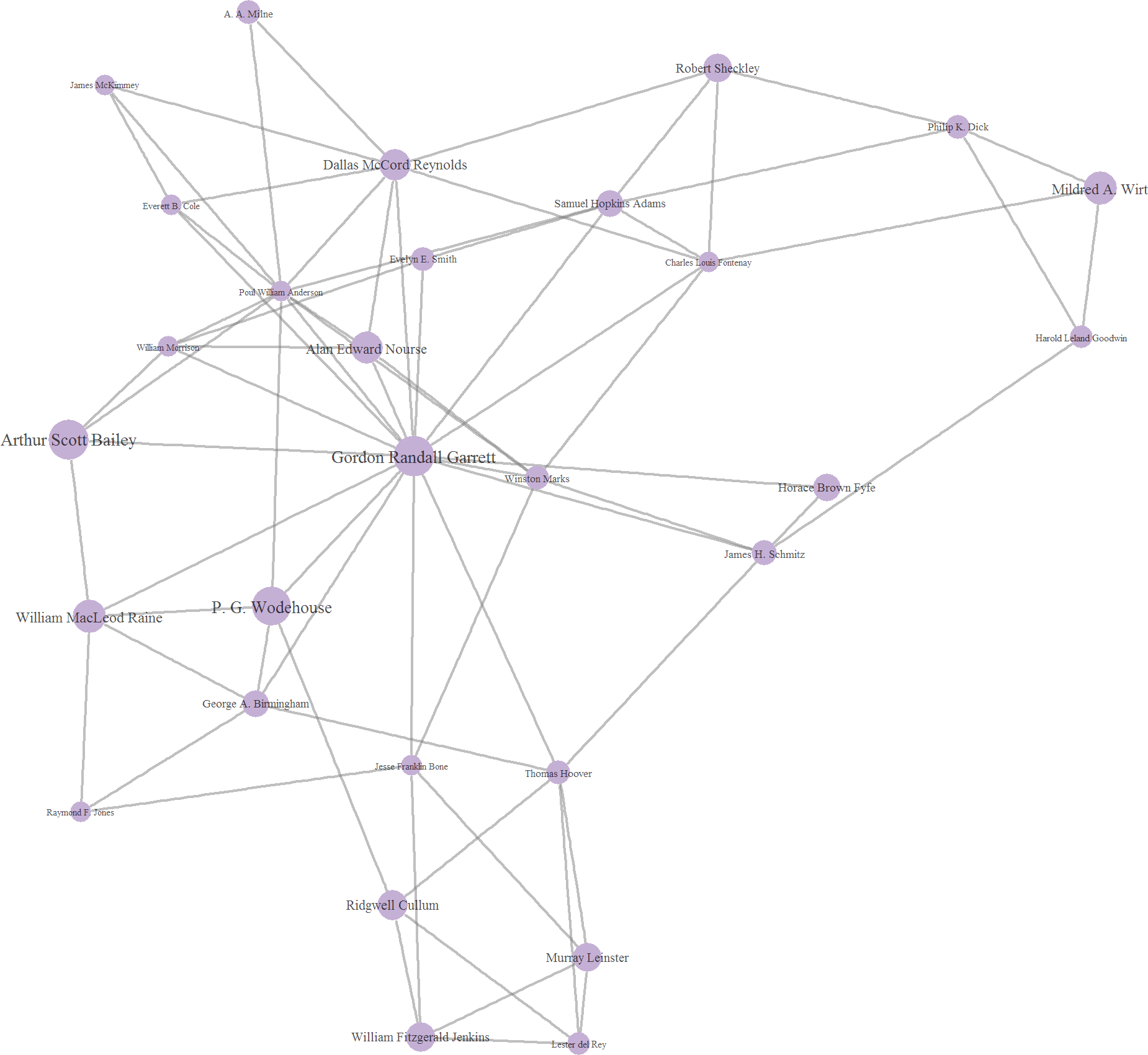
Cluster 9, like it's cousin cluster 5, is fairly peripheral to the overall network. It does, however, at least contain a few familiar names, such as P.G. Wodehouse and Philip K. Dick. In general the writers in the group seems relatively recent compared, with may writing in the mid to late 20th century. Perhaps this explains its peripheral nature, as style evolves away from the ~19th century heart of the Gutenberg collection.
Edit: it's also been pointed out to me that this cluster is highly populated by early science fiction authors.
Cluster 10
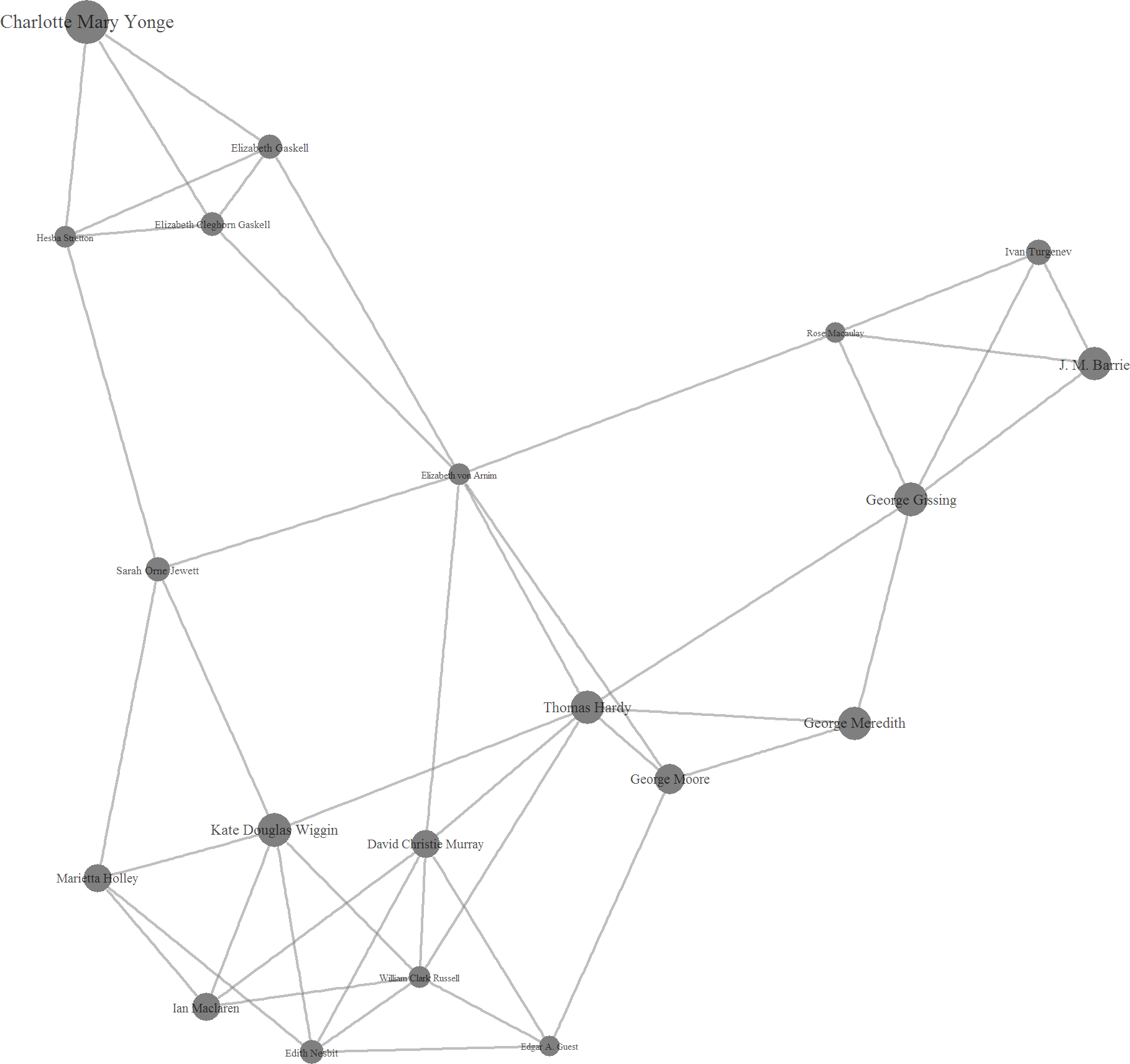
The fairly small cluster 10 is closely interwoven with a number of larger clusters near the center of the overall network. Thomas Hardy, Ivan Turgenev, and the highly prolific Charlotte Mary Younge help populate this group. Like cluster 1, this cluster appears to feature a fairly high proportion of women in comparison to some of the other groups.
Cluster 11
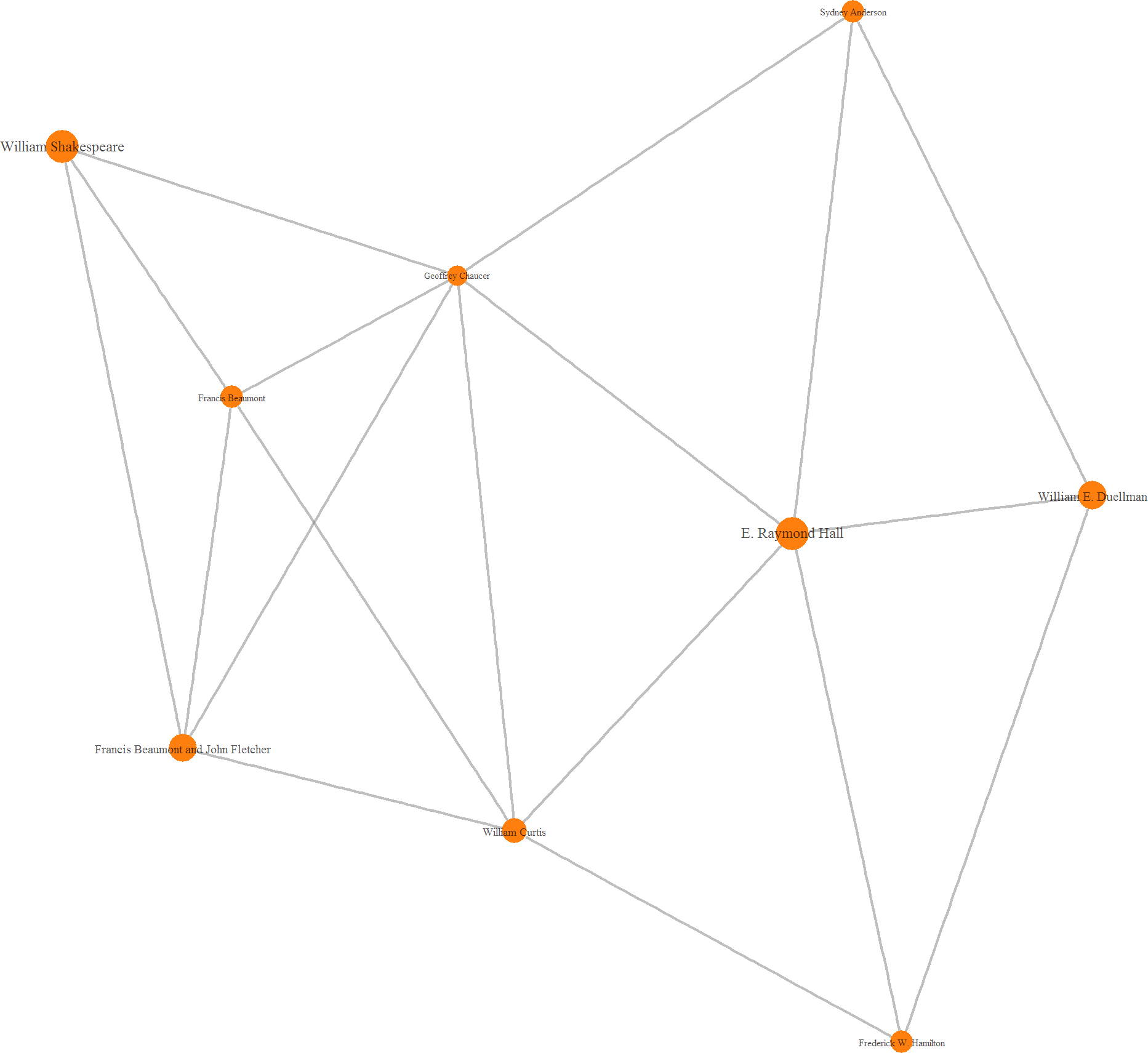
The smallest cluster, number 11, features two exceptionally well known writers, William Shakespeare and Geoffrey Chaucer. I find it surprising, given the massive influence wielded by these writers, that this cluster is fairly peripheral. However, perhaps this stems from just how far back in time these writers were. Shakespeare himself provides two of the cluster's five links to the rest of the network, with one directed at Christopher Marlowe and the other at Euripides.
Future Direction
This expedition into the world of writing styles has yielded some tantalizing results, but more needs to be done to make sense of them. From the quantitative side, I need to compile data on each of the authors in question in order to systematically investigate which sociocultural factors ultimately produced the stylistic communities we've observed here. From the qualitative perspective, I suspect I shall need to identify a collaborator who can help me make sense of my rather imperfect measures of writing style and the fascinating relationships they produce.

{kind=link}
© 2015 Mark Allen Thornton. All rights reserved.