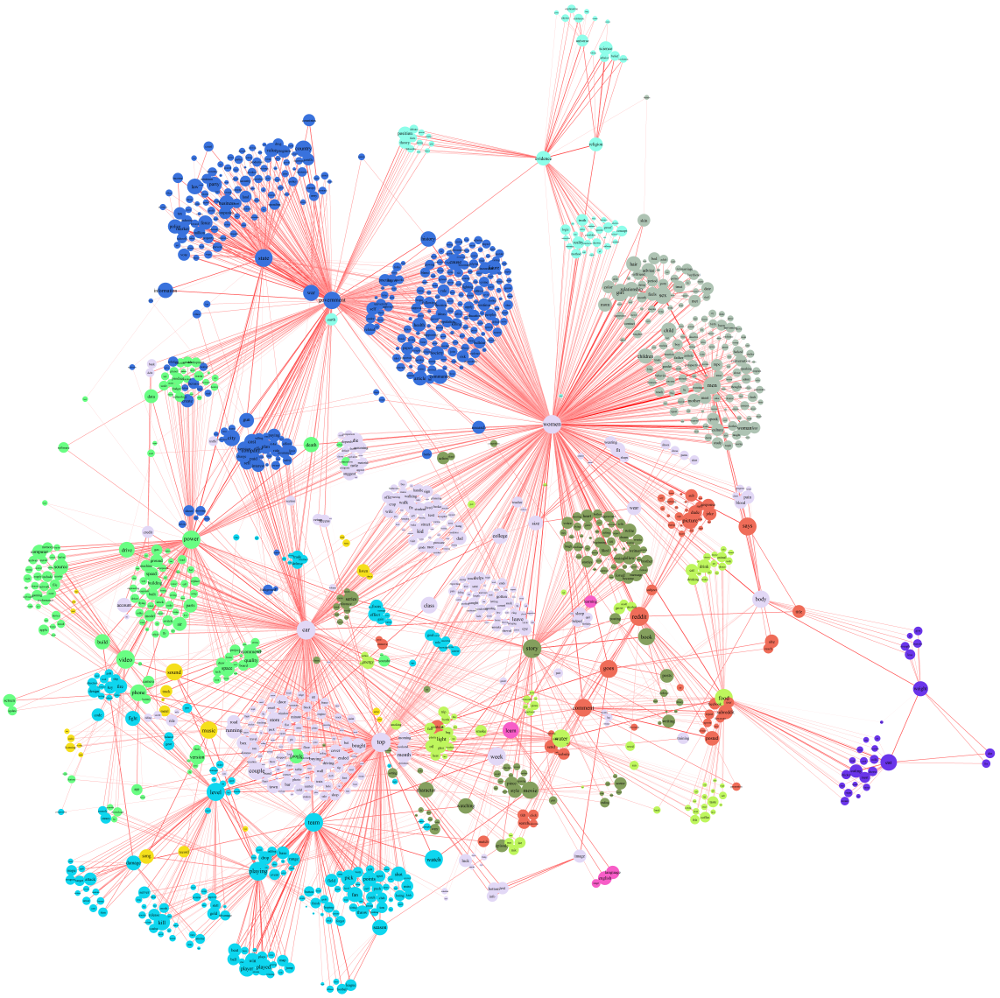
[Hover to see larger; mousewheel to change zoom level; hi-res original 9136x9120]
What interests reddit?
A network analysis of 84M comments by 200K users
Everyone has interests: topics close to their hearts that they are eager to understand and discuss. However, as billions of awkward first dates around the world can attest, different people have different - and indeed sometimes non-overlapping - interests. What can be riveting to one person might bore another to tears. This post is devoted to learning a bit more about people's interests and the connections between them.
I think many of us share the intuition that there are obvious, natural connections between certain interests. Depending on how finely we divvy up the space of possible interests, some of these connections are almost trivial: someone interested in collecting pennies from 1932 could probably be bothered about 1933 pennies too. However, there remains the enticing prospect that we may discover less obvious associations between interests that may reveal surprising aspects of society or human nature.
To gain some traction on this issue, I turned to reddit. For those of you unfamiliar with reddit, it is a wildly popular aggregation and discussion site. At the time of writing, it has over 3 million registered accounts and receives over 170 million unique visits per month. Its popular interview format known as AMA ("Ask Me Anything") has been graced by practically every kind of public figure from President Obama on down.

Reddit's format has three major conceptual elements: links, comments, and subreddits. Users (redditors) submit 'links' that might consist of anything from the url of a news story to a scientific paper to a play-by-play of a strategy game to an epic tale of IT heroism. Other users then do two things: vote up or down on the link, which together with its age determines its visibility, and potentially comment on it. The comments themselves range from the inane to the inspired, but since reddit also allows voting on comments, the worst comments (or at least the least popular) are usually hidden. Comments can also be commented upon, allowing reddit's characteristic discussion trees, which differ substantially from the purely sequential formats employed by many online forums. Finally, links and their attendant comments are organized by topic into subreddits depending on where the original poster initially submitted them. There are tens of thousands of subreddits devoted to a wide array of topics, although only a few are shown by default.
Methodology
Back in fall of 2013, I scraped approximately 84 million comments from a set of just over 200,000 redditors using PRAW. At the time, I was interested in whether different subreddits had different norms for writing style, and whether I could model users as they learned this style (the answers turned out to be yes and no, respectively). To retrieve this data with minimal bias (with respect to topic) I used PRAW's random subreddit function to obtain subreddits in a pseudorandom way. My script then stepped through the most recent 1000 links, collecting the usernames of all the commenters. With a list of redditors in hand, I then scraped their entire comment history (up to the maximum of 1000 items).
All of this text, combined with metadata about the comments (e.g. # of upvotes) adds up to a hefty 23GB in csv format. I preprocessed the text by removing a large number of content free "stopwords" (e.g. grammatical words), as well as symbols and numeric characters. I then counted the frequencies of all remaining words within a very small subsample of my dataset (0.1%). I removed words which appeared fewer than 50 times or more than 1000 times in this ~84K set of comments. I then also (very simplistically) filtered out proper names, common words other than nouns and verbs, and past tense or plural versions of words already remaining in the list. Ultimately I ended up with a set of 1,862 "feature" words, the frequencies of which I then counted in the full set of 84M comments (aggregated by user).
Given the various preprocessing I had done up to this point, this process yielded counts for each of the feature words within each of 198,542 redditors. It is worth acknowledging that these users are representative of neither the general (US) population nor even the userbase of reddit, given that reddit is not representative of the US and that the selection process was inevitably biased towards users who comment more often. However, given the sheer size of the sample, even if the results do not generalize perfectly to wider populations we can be confident that they represent the views of a large number of people.
As a final preprocessing step, I calculated the cosine similarity matrix between the feature word frequencies (across redditors). Words with very low variance in their similarity to others (i.e. words that were used very generally) were removed. Simultaneously I removed words with very high or very low median similarities (undifferentiated/polysemous words and outliers). I then calculated an adjacency matrix between the remaining set of 1444 feature words. To maximize the interpretability of the subsequent social network visualizations, each node (feature word) was given at least two edges (connections) to other nodes in the network based on the two largest elements of its row in the adjacency matrix.
The network was visualized using the igraph package for R. The width and color of the edges (lines) varies with the log (base 10) of co-occurrence of the respective words (i.e. word with [stronger] lines between them are mentioned more frequently by the same redditors), and the size of the nodes varies with the log (base 10) of the absolute frequency of the word (so for instance a word that occurred 1000x more frequently than another would have with 3x the radius). The node coloring was determined by a 5-step walktrap community finding algorithm (effectively similar to a clustering algorithm, but for social networks). Note that the colors were chosen arbitrarily, so similarity in the color of different communities should not be interpreted. The positioning of the nodes was set using the Fruchterman-Reingold algorithm, a type of force-directed plotting. Note that while similar terms are often placed close together by this algorithm, that is not universally the case, so try to avoid over-interpreting the distances between points. The edges of the graph (i.e. lines between circles) are the more accurate guide to the relationships between terms.
Results
The full network graph can be viewed at the top of this page - feel free to explore it on your own. From my own intuition, it seems as though the approach employed here proved quite successful. It clearly identifies a number of communities of interests which I hope that many people would view as natural. I'll highlight a few examples below.
Branches of Government
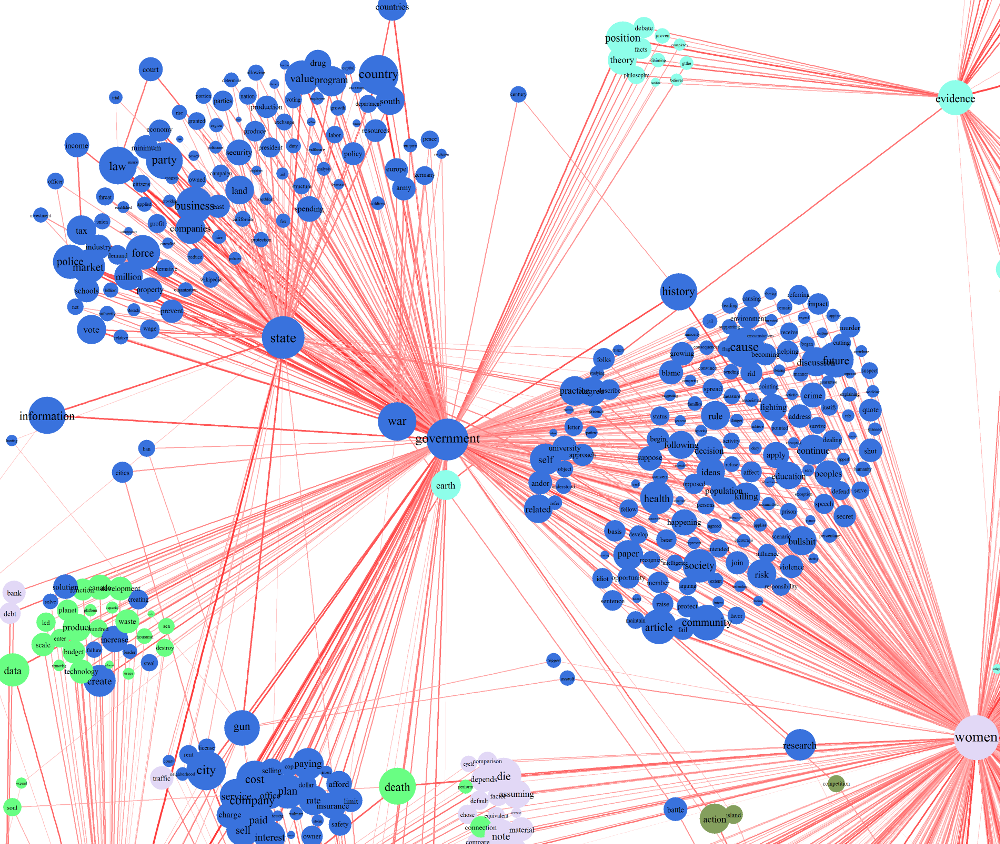
Many redditors seem to have an interested in talking about the government (dark blue). However, their interests in the topic appear to stem from a diverse set of sources. The two largest groups of features are defined by their secondary alignments with discussion of "state" and "women". The former appears to be largely focused on economics and security issues, with "business", "market", "force", and "police" numbering among the most common topics of discussion. Meanwhile the latter seems more devoted to social issues, with "health", "community", and "education" featuring prominently. Though I suspect these clusters may be correlated with the partisan liberal-conservative line, I'm not sure that that's their best characterization. Instead it seems to me more of a confirmation of "natural" division between social and economic interests.
A number of additional groups of feature words have strong connections to government. One in the "empiricist" community (light teal) seems interested in political philosophy. Another, linked to the technology community (blue-green) seems technocratically focused. Finally, another group of features (linked with "car") seems focused on issues of "low" (i.e. personal) finance rather than economics more broadly. I find the existence of this last group particularly interesting because its existence suggests a degree of disconnection between interest in "economic issues" and practical household economy.
Women. Women? Women!

Apparently women are a very common topic of discussion on reddit - perhaps not surprising for a forum (like many on the web) populated disproportionately by young men. However, while everyone seems to be talking about women, what's strikingly obvious is that not everyone is having the same conversation. On the right of the image above, we see two related clusters within the grey-green feature community - one centered on "men" and the other on "sex". Based on the words in these groups, they appear to reflect people discussing "relationships," broadly construed. Lower down, a large cluster in the darker green of the "story" feature community may be concerned with narrative by or about women. In the same grey-pink as the "women" node, we can also see two large clusters of features in the lower left. However, the nature of these clusters is less immediately obvious, at least to me.
Food and Drink
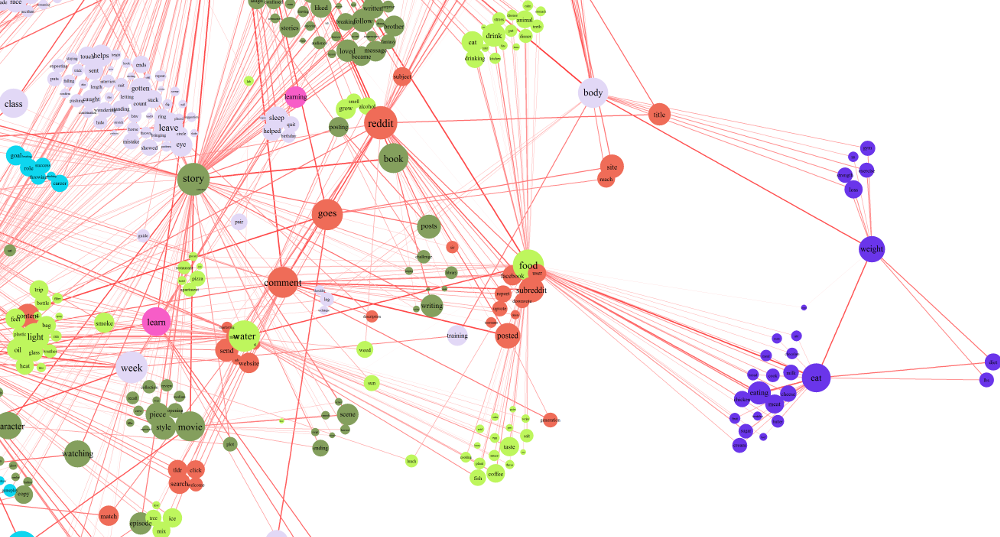
There are also redditors with strong interests in food and dieting, with the latter group particularly disconnected from discussion of other topics. In light green we seen an extended feature community centered around the nodes "food" and "water". Perhaps not surprisingly the "body" node - in grey-pink - is associated with many features in this community. Particularly interesting is the purple community on the far right, which is strongly connected to food and body but seems to be more oriented around dieting or healthy eating. Perhaps this node reflects members of weight-loss support communities on reddit? Also prominently visible in the image above is the orange community that appears to be largely devoted to talking about reddit itself.
Fun and Games

This image focuses on a large turquoise feature community devoted to a combination of sports and videogaming. The fact that these communities stick together likely reflects the similar language used in both contexts as well as potentially overlapping interests within individual redditors. In general the two clusters on the left appear somewhat more videogame-oriented while those on the right seem somewhat more aligned with traditional sports. Unsurprisingly we also see considerable links to the technology feature community in blue-green at the top of the image. Interspersed throughout is a feature community that focuses primarily on music (yellow).
Bonus Feature: Normalized Network!
In addition to the primary network graph discussed above, I produced a graph that is essentially 'normalized'. While the main graph is predicated upon occurrence and co-occurrence of words within redditors, this graph is based simply on the cosine similarity (very similar to correlation) between the counts of the different feature words across redditors. As a result, the influence of absolute word frequency - which drives much of the earlier graph - is substantially diminished. Instead of granting (at least) two edges to every node, this graph merely selects the top 0.1% of all connections (since all connections are now on the same scale). Nodes without any connections were removed from the graph. The shape of the network is obviously quite different, but close examination reveals many parallels with the previous graph. While some of the connections introduced here are rather trivial, in general I think this graph does slightly more to reveal what one might call the "fine structure" of people's interests. Note that edge color now varies linearly with cosine similarity, and that node size now varies with the log (base 10) of the node's degree centrality (i.e. number of connections to other nodes).

Data sharing
After receiving a number of requests, I've decided to make the raw data behind this post publicly availiable. Since the data is accessible via the reddit API anyway, this is really just a convenient way to access it without burdening reddit's servers. There's not really a question of privacy here, since comments are posted publicly with the express intention of allowing others to view them. Although reddit usernames are as anonymous as users choose to make them, I've replaced them with arbitrary numeric IDs to make it more difficult to use the data to target individuals. Below are links to 10 zipped csv files. Each row is a different comment. There are eight columns: user ID, link title, subreddit, data collection timestamp (seconds since epoch), post timestamp, upvotes, downvotes, and comment text. Note that the user IDs start from 1 in each of the 10 files, so ID 1 from one file is not the same user as ID 1 from another file.

{kind=link}
{kind=link}